

AIアウトバウンドコールを実現する(後編):Gemini Live APIへの移行による自然な会話の実現



こんにちは、株式会社クーリエでテックリードを担当しているMです。前編では、Dialogflowを使った第1世代のシステムにおいて、「音声生成の遅延(4秒問題)」や「チャットボット特有の会話の不自然さ」に苦闘した話をご紹介しました。
後編となる今回は、その課題を一気に解決したGemini Live APIの導入(第2世代)と、運用を安定させるためのアーキテクチャ刷新(第3世代)についてお話しします。
目次
第2世代:Gemini Live APIによるブレイクスルー
第1世代の課題を踏まえ、私たちは大規模な方針転換(ピボット)を決断しました。 Dialogflowを廃止し、Gemini Live APIを採用するという選択です。
技術的転換点:Native Audio
ちょうどこの頃、Gemini Live APIの中で「Native Audio」というモデルが新しく採用されました。これは、Geminiが音声入力を直接理解し、音声として応答できる仕組みです。
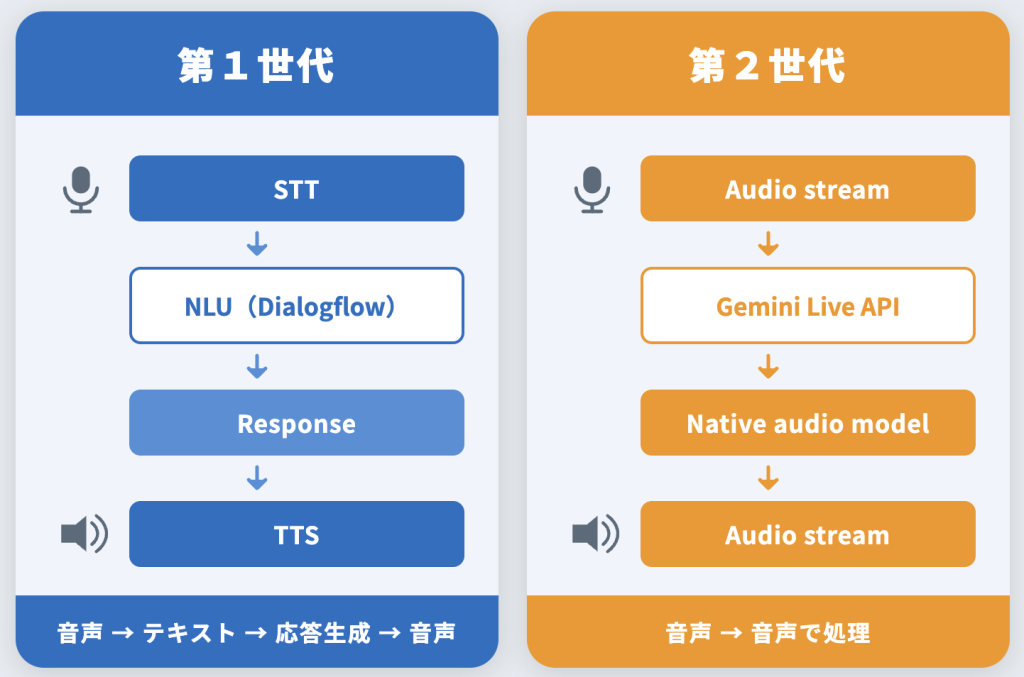
従来の音声AIは、以下のような複数のコンポーネントで構成されていました。
- 第1世代:STT → NLU(Dialogflow) → response → TTS
しかしNative Audioでは、単一モデルが音声を直接処理します。
- 第2世代:Audio stream → Gemini Live API → Native audio model → Audio stream
これにより、従来は複数のサービスに分かれていた処理が統合され、より自然で低遅延な音声対話が可能になりました。
改善効果
- 圧倒的な低遅延化:これまで4〜5秒かかっていた応答が、人間と会話しているのと体感差がないレベルまで速くなりました。
- 割り込み(Turn-taking)の実現:相手が話し始めた瞬間にAIが発話を止める「割り込み」が可能になりました。「あ、ごめん、そうじゃなくて」といった訂正にも自然に対応できます。
- コストパフォーマンスの維持:Dialogflowのライセンス費用が不要になりました。
Live API の基礎知識(Google AI Studioで体験)
「いきなり実装するのはハードルが高い」と感じる方のために、このLive APIの凄さをブラウザだけで体験する方法をご紹介します。 私たちが実際にコードを書く前に、このツールの「Stream mode」を使って検証した手順です。なお、本手順は2026年3月5日時点のものです。Google AI SudioのUIはバージョンアップされる可能性がありますので、ご注意ください。
1. ツールの準備
Googleが提供するプロトタイピング環境Google AI Studioを使用します。 ブラウザ(Chrome推奨)で
aistudio.google.com/live にアクセスします。
2. セットアップ
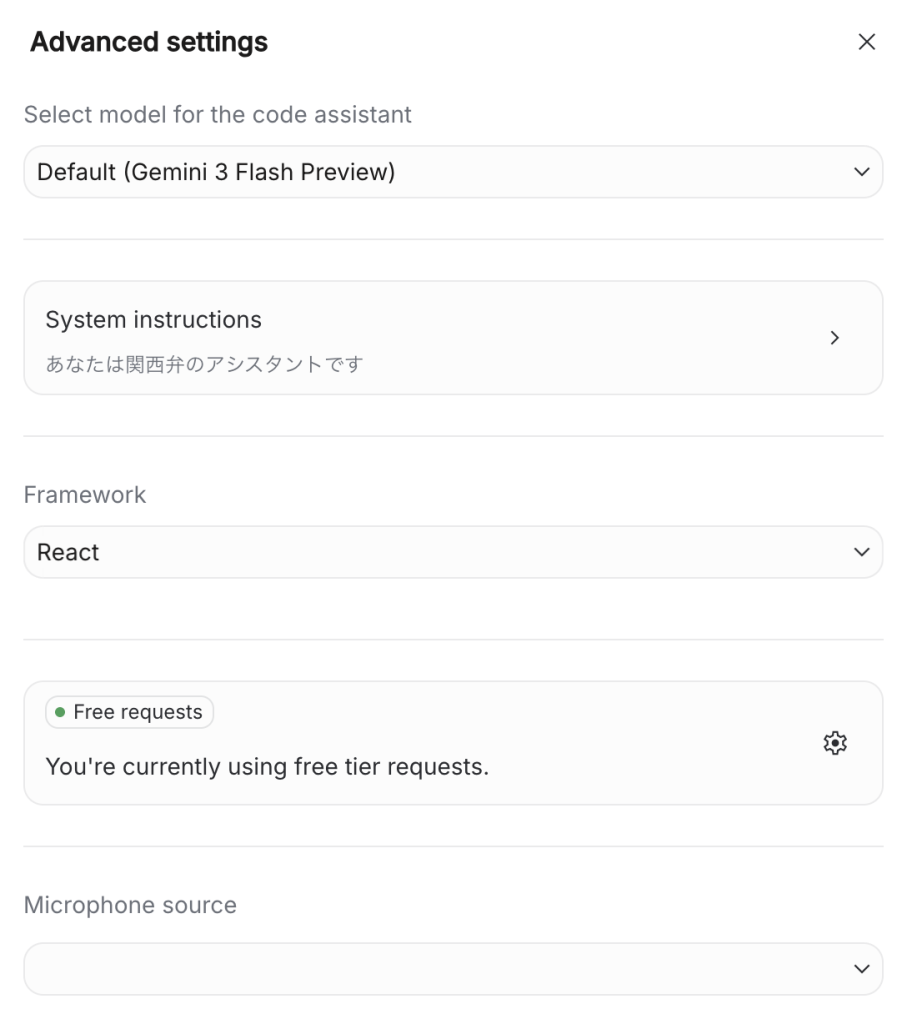
左メニューの「Start」からアプリの内容について記載します。歯車マークを押して詳細を設定することも可能です。
- Model:Gemini 3 Flash Preview など、Live対応モデルを選びます。
- System Instructions:ここに「あなたは関西弁のアシスタントです」などと書けば、キャラ付けも可能です。
- Framework:使用したいFrameworkを選びます。
3. いざ体験!「割り込み」を試す
[Start Conversation] ボタンを押してマイクを許可すると、会話が始まります。 ぜひ試していただきたいのが、「AIが喋っている途中に被せて話す」ことです。
従来のボットなら無視して喋り続けるところを、Live APIなら即座に止まって「はい、何でしょう?」と耳を傾けてくれます。 これが、私たちが導入を決めた最大の理由である「Turn-taking」機能です。

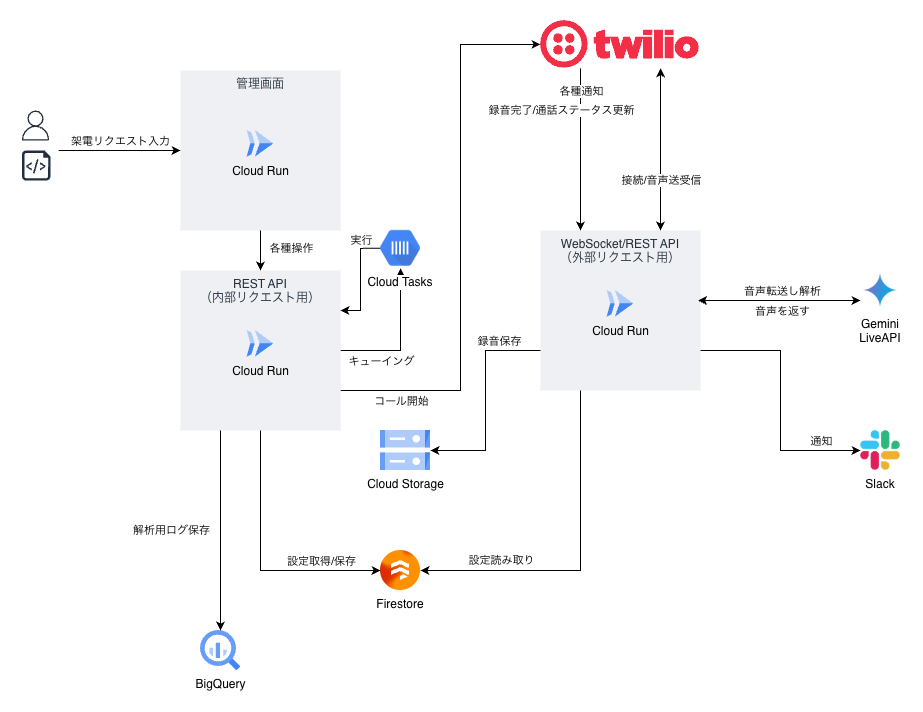
第3世代:マイクロサービス的アプローチと運用安定化
第2世代で性能面の問題は解決しましたが、運用を続ける中で「システムの複雑化」という新たな課題が浮上しました。 そこで第3世代では、機能追加よりもアーキテクチャの整理を行いました。
1. エージェントのインスタンス分割
当初は1つの巨大なプロンプトですべてを処理していましたが、「見学調整」の目的のためエージェント(インスタンス)を物理的に分割しました。これにより、各エージェントの役割が明確になり、管理効率が向上しました。
2. 接続処理とAIロジックの分離
Websocket接続を受け付けるサーバーと、実際のAI処理を行う部分を分離しました。これにより、特定のエージェントにリクエストが集中しても、システム全体が共倒れするリスクを回避できるようになりました。
3. 可観測性の向上 (Slack通知)
架電完了時やトラブル発生時に、即座にSlackへ通知が飛ぶ仕組みを実装し、オペレーションの透明性を確保しました。
開発の裏側:その他の苦労話
成功談だけでなく、開発中に直面した泥臭い課題も共有します。
1. 音声処理の「沼」
最も苦労したのは音声フォーマットの変換です。 WebM、WAV、PCMなど、各APIやブラウザが要求する形式が異なり、変換処理の実装には多くの時間を費やしました。変換設定を少し間違えるだけで「音割れ」や「再生速度異常」が発生するため、非常にデリケートな調整が求められました。
2. AIモデルの「サイレントアップデート」
AIならではのリスクとして、モデルの挙動が予告なく変わる現象に直面しました。 例えば、日本語で指示しているにも関わらず、ある日突然AIが英語で応答し始めるといった事象です。 この経験から、コードのバグだけでなく「AIの挙動」そのものを監視する自動テスト(E2Eテスト)の導入が不可欠であるという結論に至りました。
まとめ
初期に苦労して実装した「相槌の制御」などは、AIモデル自体の性能向上によって不要になったものもあります。しかし、そこで培った「音声データの扱い」や「Cloud Runでのスケーリング技術」、「キャッシュ戦略」といった知見は、現在のシステムにも色濃く受け継がれています。
AI技術は日進月歩ですが、単に新しいAPIを使うだけでなく、運用コストや耐障害性を含めたトータルなシステム設計が重要であることを、このプロジェクトを通じて改めて学びました。




