

AIアウトバウンドコールを実現する(前編):Dialogflow活用と「4秒の壁」の突破



こんにちは、株式会社クーリエでテックリードを担当しているMです。 弊社では現在、AIを用いた電話業務の自動化(AI架電システム)の開発に取り組んでいます。
本記事では、その立ち上げから現在に至るまでの技術的な変遷を、前編・後編の2回に分けてご紹介します。 前編となる今回は、Dialogflowを中心に構築した初期システム(第1世代)の話と、そこで使用した技術であるDialogflow CXの基礎的な構築手順について解説します。
目次
プロジェクトの概要
弊社では「再現性と仕組み化」をバリューに掲げ、日々業務効率化を進めています。 その一環として、介護施設の契約者向けに 「見学予約の承認忘れ」を防ぐためのリマインドコールを自動化するプロジェクトに着手しました。
従来は担当者が手作業で架電を行っていましたが、件数が増えるほど対応負荷が高まり、抜け漏れや対応遅延のリスクも顕在化していました。こうした属人的なオペレーションを解消し、安定した品質で確実にフォローできる体制を構築するため、AIによる自動架電の仕組みを導入することにしました。リストアップされた架電先に対し、AIがオペレーターの代わりに電話をかけ、予約確認を行うシステムです。
本プロジェクトの野心的な点は、アウトバウンドコール(架電)のAI化に踏み込んだことです。インバウンドコール(受電)は、顧客側の目的が限定的であり、自動音声応答(IVR)などの土壌もあったため、AI化が比較的受容されやすい傾向にあります。対してアウトバウンドコールは、相手の反応が予測困難な上、AIによる発信が心理的な不信感を招きやすく、技術的・運用的な難易度が極めて高いテーマといえます。
単なる自動音声ではなく、相手の反応に応じて会話を成立させる対話型の仕組みとして、技術的な壁や運用上の制約を一つずつ乗り越えながら、実用レベルでの自動架電を実現しました。
当時の技術選定:なぜDialogflowだったのか?
プロジェクトを開始した当初(2024年初頭)、Google Cloud上で会話型AIを作るならDialogflowが標準的な選択肢でした。
現在でこそGemini Multimodal Live API(2024年末プレビュー公開)のような、音声・動画をリアルタイムに処理できるAPIがありますが、当時はまだ存在しませんでした。 そのため、「チャットボットエンジン(Dialogflow) + 音声認識/合成API」 という組み合わせが、当時の技術スタックとしては最善のアプローチでした。
第1世代システムの構成と課題
Dialogflowで対話ロジックを作り、それを電話システムと繋ぎこんで架電システムを構築しました。 しかし、実際に動かしてみると、電話ならではの致命的な課題に直面しました。
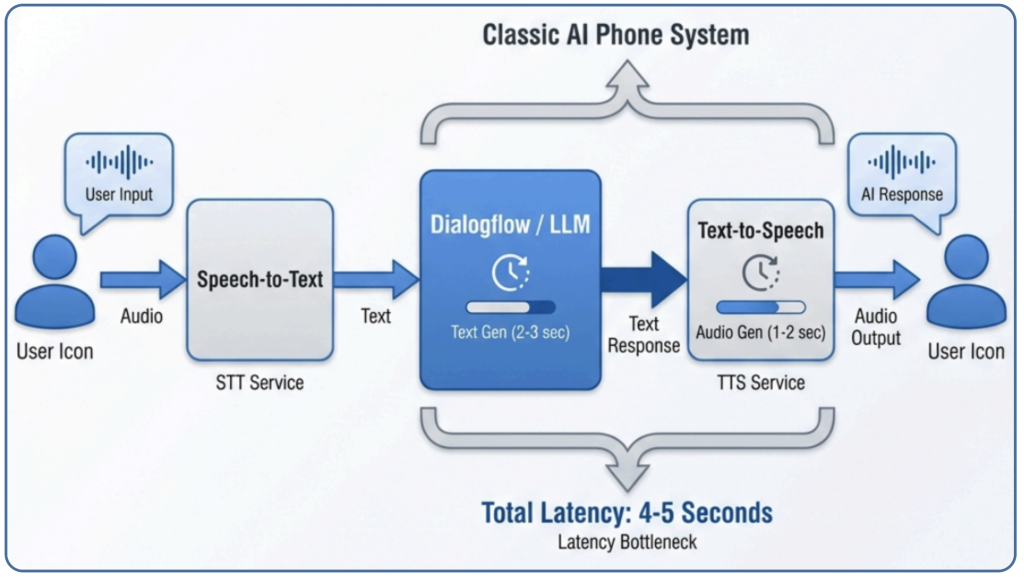
直面した「4秒問題」
最も大きな問題はレイテンシ(応答速度)です。 仕組み上、以下の処理時間が積み重なります。
- Dialogflowがテキストを生成:2〜3秒
- OpenAI TTSが音声を生成:1〜2秒
- 合計:4〜5秒
電話での4秒の沈黙は放送事故レベルです。 テスト架電でも「電波が悪いのかと思った」「会話のリズムが掴めない」という厳しいフィードバックを受けました。
独自の解決策:音声キャッシュ機構
そこで導入したのが、音声キャッシュ機構です。 「お世話になっております、株式会社クーリエの〇〇です」といった定型句・挨拶に関しては、毎回AIに生成させる必要がありません。
私たちは、一度生成した音声データをDBに保存し、次回以降はTTSをスキップしてその録音データを再生する仕組みを作りました。 この地道な工夫により、定型文に関しては遅延をほぼゼロに短縮し、なんとか実用ラインに載せることができました。この段階での実証実験では、約20〜30%の確率で目的(見学予約の確認)を完了させることができました。
Dialogflow CX の基礎知識(サンプル構築)
ここで、今回採用した Dialogflow CX の仕組みを理解していただくために、私たちが検証時に作成したような「簡単なQ&Aボット」を実際に作る手順をご紹介します。 「架電システムの概要を答えてくれるBot」を例に、その構造を見てみましょう。なお、本手順は2026年3月3日時点のものです。Dialogflow CXのUIはバージョンアップされる可能性がありますので、ご注意ください。
1. Dialogflow CXの設定
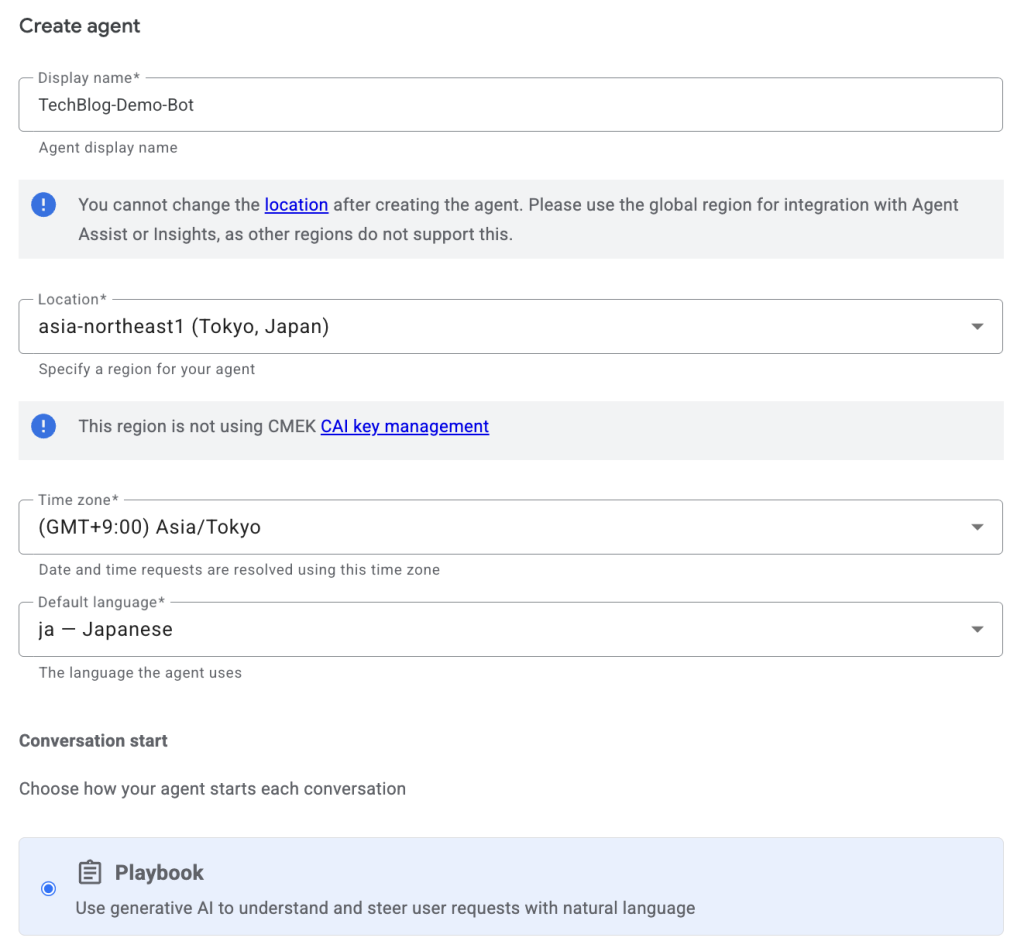
1-1. エージェントの作成
まず、Dialogflow CXコンソールで「エージェント(ボットの箱)」を作ります。 構築タイプには、最新の
Generative AI機能を使う「Playbook」を選択しています。
- Display name: TechBlog-Demo-Bot
- Location: global (または asia-northeast1 )
- Time zone: (GMT+9:00) Japan Standard Time
- Default Language: ja – Japanese
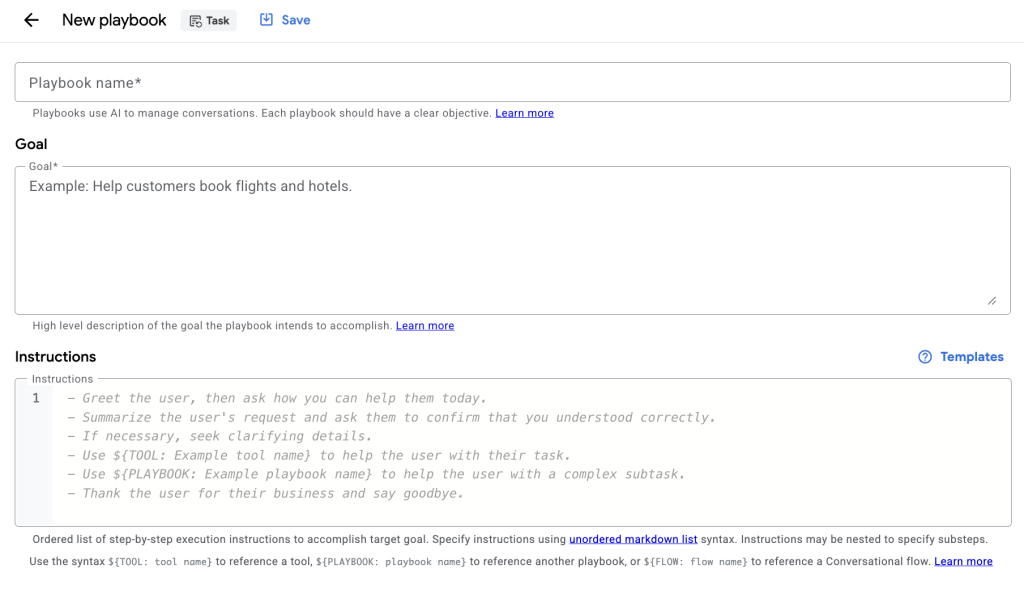
1-2. タスク(ユーザーの意図)の定義
Dialogflow CX の Generative AI 機能では、「Playbook」という単位で LLM の振る舞いを定義します。その中核にあるのが Task です。
一言で言えば、Task とは「その Playbook が達成すべき具体的なミッション」を定義する領域です。
Flow が会話の遷移(状態管理)を担うのに対し、Playbook は知的処理を担当します。そして Task は、その知的処理の「ゴール」を明示するものです。
1-3. 返答の設定(Examples)
Dialogflow CX の Playbook では、Task によって「何を達成するか」を定義します。
その Task の中にある Examples は、LLM にどう振る舞ってほしいかを具体例で示す領域です。
Task が「目的の定義」だとすれば、Examples は「理想的な実行サンプル」です。
図4. Example の作成 1-4. Flow の設定
Dialogflow CX における Flow(フロー) とは、会話を「状態遷移」として管理するための大きな単位です。一言でいえば、会話の「章(チャプター)」を定義する仕組みです。
先ほど 2 で設定した Playbook を指定することで、最小単位の会話が設定できます。
図5. Flow の設定 以上でDialogflowでの設定は完了です。
2. API経由での呼び出し
2-1. セッションの作成
エージェントは「セッション」という単位で会話を管理します。
任意のsession-idを指定し、以下の形式でリクエストを送ります。API エンドポイント
POST https://{location}-dialogflow.googleapis.com/v3/projects/{project-id}/locations/{location}/agents/{agent-id}/sessions/{session-id}:detectIntent2-2. リクエスト例(テキスト入力)
以下のような json 形式でリクエストを送信します。
リクエスト例
{ "queryInput": { "text": { "text": "どんなシステムですか?" }, "languageCode": "ja" } }
2-3. 実行確認(curl例)
curlで実行確認する場合は、以下のようなリクエストで確認することができます。
AGENT_IDについては、表示名ではなく管理画面のURLに含まれるUUIDになりますのでご注意ください(agents/{AGENT_ID}/の形式)。
curl での実行例
curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "X-Goog-User-Project: PROJECT_ID" \ -H "Content-Type: application/json" \ https://LOCATION-dialogflow.googleapis.com/v3/projects/PROJECT_ID/locations/LOCATION/agents/AGENT_ID/sessions/test-session:detectIntent \ -d '{ "queryInput": { "text": { "text": "どんなシステムですか?" }, "languageCode": "ja" } }'
2-4. レスポンス例
APIを実行すると以下の例にあるようなJSON形式のレスポンスが返ってくるのを確認できます。
レスポンス例
{ "queryResult": { "responseMessages": [ { "text": { "text": [ "音声認識・音声合成APIと連携してリアルタイム応答を実現します。" ] } } ] } }
まとめ
第1世代では、Dialogflowという確実な技術をベースにしながら、遅延という問題に対してキャッシュ等の工夫で立ち向かいました。 しかし、「チャットボットと音声合成の継ぎ接ぎ」である以上、超えられない壁があったのも事実です。
次回後編では、この壁を一撃で破壊したGemini Multimodal Live APIの衝撃と、実運用に耐えうるシステムへと進化した第2、第3世代のシステム開発について詳しく解説します。
(後編へ続く)




