

オフライン広告の効果を可視化せよ! Meta社製OSS「Robyn」で挑むMMM(Marketing Mix Modeling)実録



目次
はじめに
こんにちは、株式会社クーリエの技術開発部です。 弊社では「みんなの介護」という老人ホーム検索サイトを運営しており、多くのユーザーに届けるためにマーケティング活動に力を入れています。
老人ホームを探していらっしゃるのは入居者ご本人かその子供であり、年齢層は高めです。そのため、スマートフォンやPCになじみがなく、web広告ではアプローチしきれないケースも。そこでテレビCM、街頭看板、チラシといったオフライン広告も積極的に展開しています。
ここで常に課題となるのが、「オフライン広告の効果測定、難しすぎ問題」です。
先日、この長年の課題に対してMMM(Marketing Mix Modeling)という統計的アプローチで挑んでみました。
本記事では、Meta社が公開しているOSS「Robyn」を活用した実例と、そこで直面した「泥臭い」現実について共有します。
直面した課題:オフライン広告の効果が見えない
私たちはこれまで、オフライン広告の効果を以下のような「ミクロ分析」で評価していました。
- チラシや新聞:QRコードからの流入数
- CM:放送前後の地域別セッション数のアップリフト(増加分)
これらは短期的な効果を見るには有用ですが、以下のような限界がありました。
- ブランド資産への寄与が見えない: 即時のWeb来訪だけでなく、 「名前を覚えたから後で検索した」といった間接効果が評価できない。
- 長期効果の過小評価: 一度見たCMの効果が数日続く(残存効果)ことなどを考慮できていない。
「このままではオフライン広告の真の価値(あるいは無駄)が判断できない」という危機感から、マクロな視点で予算配分の最適解を導き出すMMMの導入を決定しました。
解決策:Meta社製OSS「Robyn」の採用
ツール選定の理由
MMMを実施するためのツールとして、今回はMeta社が公開しているRobynを採用しました。
選定理由は以下の3点です。
- タイミング: 検討当時(2025年1月頃) 、GoogleのMeridian(旧LightweightMMM)がまだ公開されていなかったため。
- 可視化の強力さ: レポーティング機能やCSV出力が充実しており、マーケティング担当者などのステークホルダーへの説明がしやすそうだった(下図参照) 。
- 標準機能の充実: Adstock(残存効果)やSaturation(収穫逓減)といった必須パラメータの推定が標準で備わっている。
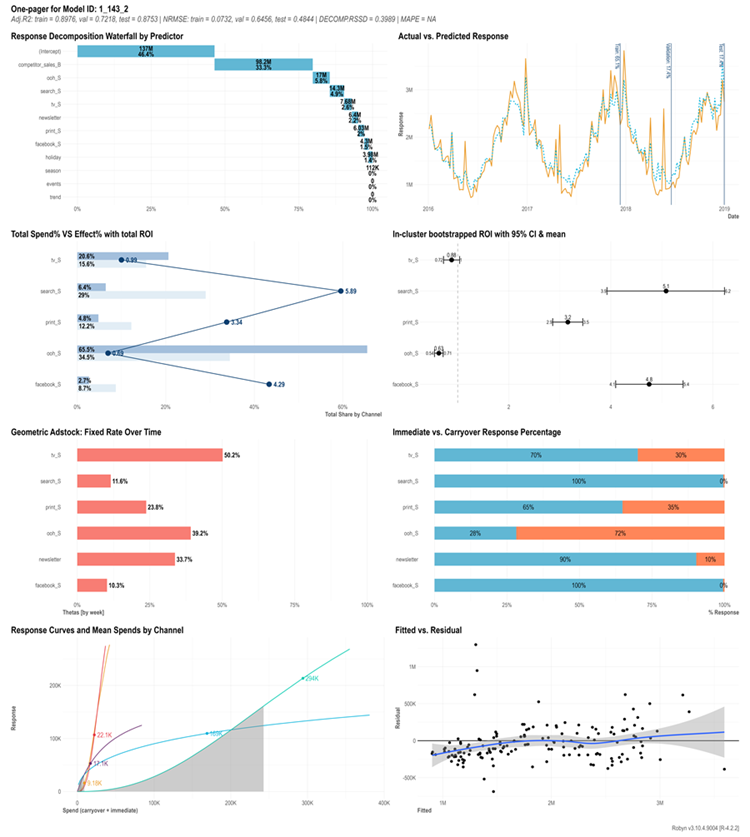
このように、どの広告がどれくらい寄与したか、予算配分をどう変えれば良いかが視覚的に分かります。
実装と工夫
RobynはR言語のライブラリです。当初は「Pythonで完結させたい」という思いからPythonラッパーであるRobynPyを試しましたが、R版と結果が一致しないなどの挙動が見られたため、おとなしくGCP Vertex AI Workbench上にR環境を構築しました。
独自の予算最適化ロジックの実装
Robynには予算最適化機能もついていますが、私たちはあえてこれを使わず 、Pythonで独自の最適化処理を実装しました。
理由は、 「指名検索(Organic Search) 」への間接効果をモデルに組み込むためです。
通常の単一モデルでは、 「CMを見る -> 検索する -> CVする」という流れの「CM -> 検索」の部分の効果が過小評価されがちです。そこで、以下の2段階モデルを構築しました。
- 問い合わせモデル: 「検索数」などを説明変数に入れて学習。
- 検索モデル: 「検索数」自体を目的変数とし、各広告の寄与を学習。
これらを組み合わせることで、検索経由の間接的な広告効果も含めた最適化を行いました。
以下は、最適化に使用したPythonコードの一部です。Robynが出力した pareto_aggregated.csv などのパラメータファイルを読み込み、SciPyなどのソルバで最小化(最大化)させています。
目的関数の実装例:
import pandas as pd import numpy as np # ... (データ読み込み処理) ... # 独自定義した目的関数(これを最大化する) def objective(x): total = 0.0 # ... (中略) ... for i, column in enumerate(target_paid_media_columns): # --- 1. 直接的な問い合わせへの寄与 --- # Robynから取得したパラメータ(beta, alpha, gamma, theta)を使って計算 beta_c = float(pareto_aggregated_contact.loc[...].values[0]) x_ad_c = avg_adstock_geometric_from_total(x[i], N_PLAN, theta_c) x_m_c = get_hill_xm_from_training_range(...) total += beta_c * hill(x_ad_c, alpha_c, x_m_c) # --- 2. 検索(Organic)を経由した間接的な寄与 --- # CM予算(x) -> 検索数(organic_lift) -> 問い合わせ(totalへの加算) beta_o_paid = float(pareto_aggregated_organic.loc[...].values[0]) organic_lift = beta_o_paid * hill(x_ad_o, alpha_o, x_m_o) # paid -> organic total += coef_org_in_contact * organic_lift # organic -> 問い合わせ return -1.0 * total # 最小化ソルバを使うため、符号を反転
運用でぶつかった3つの壁
「これで予算配分も完璧だ!」と思ったのも束の間、現実はそう甘くありませんでした。
1. データ準備が全工数の50%
「MMMはデータ準備が命」とよく言われますが、これは本当でした。 広告の請求データはあっても、実際にユーザーの目に触れた露出データ(インプレッション発生日ベースのデータ)が一元管理されていなかったのです。
各担当者がバラバラのExcelで管理していたデータを、Robynが読み込める形式に整形する作業に、プロジェクト期間の半分を費やしました。 ※現在は、最初からMMMに使える形式でデータを蓄
積する運用に変更しています。
2. データ期間が足りない(季節性の罠)
Robyn公式の推奨データ期間は「週次で2年以上」です。しかし今回は、日次データで約1年分しか用意できませんでした。
これにより、季節変動(Seasonality)の誤学習が発生しました。 例えば、年末年始はサービスの特性上問い合わせが減るのですが、たまたまその時期に出稿していなかった広告があると、モデルは「この広告を出さなかったから問い合わせが減ったのだ(=この広告の効果は絶大だ) 」と勘違いしてしまうのです。
3. モデル選択という「人間依存」タスク
Robynは、ベイズ統計的なアプローチ(Meridianなど)とは異なり、大量のモデル候補を出力し、人間がその中からベストな一つを選ぶという設計思想です。
一度モデルを決めればあとは自動運用…と思っていたのですが、データ更新のたびに学習結果(係数)が大きく変わってしまうため、毎回「どのモデルを信じるか」という恣意的な選択を迫られることになりました。これでは運用の負荷が高すぎます。
まとめ:それでもやってみて良かったこと
苦労の多いMMMプロジェクトでしたが、収穫もありました。
ある時、モデルの予測値と実績値が特定の期間だけで大きく乖離したことがありました。
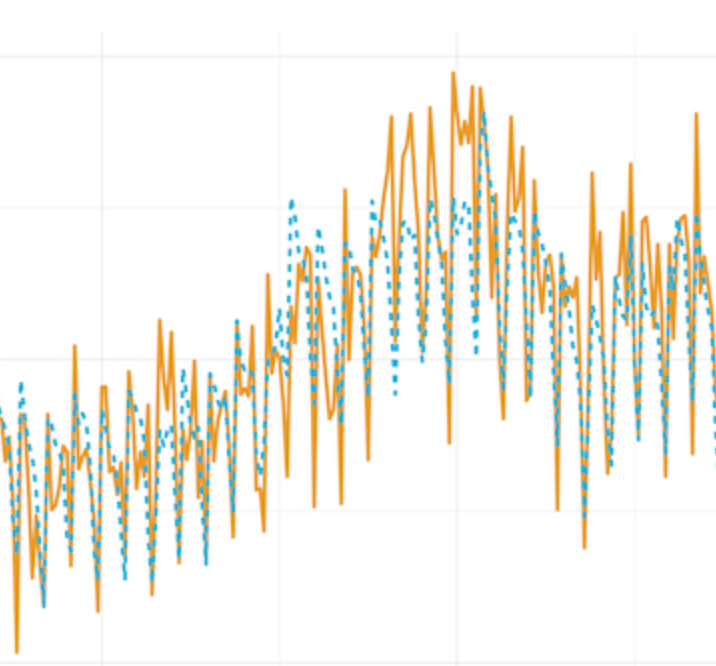
調べてみると、その期間だけ問い合わせフォームのUI仕様変更が行われていたことが判明しました。これは、モデルが広告以外の外部要因(UI変更)を正しく「異常」として検知できた(=フィッティング自体は正しく機能してい
た)ことの証明です。これを見た瞬間、 「Robyn、意外と信頼できるかも」と感じました。
今回の知見をまとめます。
- データ準備は最優先: 露出ベースのデータを日頃からきれいに貯めておくことが、MMM成功の8割を握ります。
- データ量は正義: 週次で2年分、最低でも季節変動を吸収できるだけの期間がないと、モデルは簡単に騙されます。
- 運用コストを見積もる: 「作って終わり」ではなく、定期的なモデル再学習と選定プロセスまで含めた運用設計が必要です。
現状、私たちのMMMはまだ「占い」レベルの信頼度にとどまっていますが、データが十分に蓄積されたタイミングで再チャレンジする予定です。
オフライン広告の効果測定に悩む皆さんの、第一歩の参考になれば幸いです。




